Chapter Two
Incident Response Process & Procedures
When most of us hear terms like “incident response process and procedures” our eyes tend to wander, and our attention starts to drift. Yawn, right?
But, at the same time, it’s a necessary evil these days. How many times do you have to hear that data breaches are inevitable in a single day? Especially at an RSA conference, not to mention your LinkedIn news feed or the front page of USA Today.
Consider this chapter your resource guide for building your own incident response process, from an insider who’s realized - the hard way - that putting incident response checklists together and telling other people about them can honestly make your life easier. In fact, it may even help you keep your sanity. Believe me.
So, what is an incident response process?
At the end of the day, it’s a business process. In fact, an incident response process is a business process that enables you to remain in business. Quite existential, isn’t it? Specifically, an incident response process is a collection of procedures aimed at identifying, investigating and responding to potential security incidents in a way that minimizes impact and supports rapid recovery.
Take it from me and many of my friends who wear these battle scars… the more you can approach an incident response process as a business process - from every angle, and with every audience - the more successful you will be.
What’s the difference between an incident response process and incident response procedures?
Even though the terms incident response process and incident response procedures are often used interchangeably, we’ve used them in specific ways throughout this guide. An incident response process is the entire lifecycle (and feedback loop) of an incident investigation, while incident response procedures are the specific tactics you and your team will be involved in during an incident response process.
Love This Guide?


Try AlienVault USM for Free
Accelerate your threat detection and incident response with all of the essential security controls you need in one easy-to-use console.
Incident Response Process: Preparation
Before even thinking about the specific incident response procedures you’ll need to set yourself up for success by doing the following:
- Prioritize your assets, capture baselines
Ask yourself and your leadership, what are our most important assets? In other words, what servers, apps, workloads, or network segments could potentially put us out of business if they went offline for an hour? A day? What information could do the same if it fell into the wrong hands?
By the way, the assets that you consider as important to the business may not be the ones that your attacker sees as important (more on that concept in Chapter Three).
- Develop a list of the top tier applications, users, networks, databases, and other key assets based on their impact to business operations should they go offline, or become compromised in other ways.
- Quantify asset values as accurately as possible because this will help you justify your budget.
- Finally, capture traffic patterns and baselines so that you can build an accurate picture of what constitutes “normal.” You’ll need this foundation to spot anomalies that could signal a potential incident.
- Connect, communicate & collaborate
Meet with executive leadership, share your analysis of the current security posture of the company, review industry trends, key areas of concern, and your recommendations. Set expectations on what the IR team will do, along with what other companies are doing, as well as what to expect in terms of communications, metrics, and contributions. Find out the best way to work with the legal, HR, and procurement teams to fast track requests during essential incident response procedures.

- Direct & document actions, deliver regular updates
Answer these questions for each team member:
- What am I doing?
- When am I doing it?
- Why am I doing it?
The incident response team members - especially those who are outside of IT - will need ample instruction, guidance, and direction on their roles and responsibilities. Write this down and review it individually and as a team. The time you spend doing this before a major incident will be worth the investment later on when crisis hits. Everyone involved, especially the executive team, will appreciate receiving regular updates, so negotiate a frequency that works for everyone and stick to it.
Incident Response Process Methodology: The OODA Loop
It’s not unusual to see a lot of InfoSec warriors use military terms or phrases to describe what we do. Things like DMZ and “command and control” are obvious examples, but one of the best that I’ve seen for incident response is the OODA Loop. Developed by US Air Force military strategist John Boyd, the OODA loop stands for Observe, Orient, Decide, and Act.
Imagine you’re a pilot in a dogfight. You need a tool to determine the best way to act as quickly as possible when you’re under attack. It’s a useful analogy when applied to an incident response process.

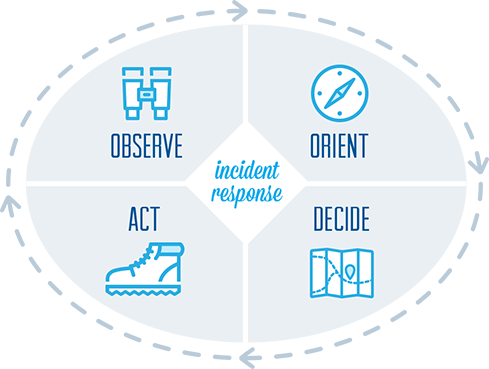
Putting the OODA Loop into Your Incident Response Process
Observe: Use security monitoring to identify anomalous behavior that may require investigation.
Log Analysis; SIEM Alerts; IDS Alerts; Traffic Analysis; Netflow Tools; Vulnerability Analysis; Application Performance Monitoring
- What’s normal activity on my network?
- How can I capture and categorize events or user activity that aren’t normal?
- And that require my attention now? How can I fine-tune my security monitoring infrastructure?
The more observations you can make (and document) about your network and your business operations, the more successful you’ll be at defense and response.
Bonus tip: Share additional observations with executives that could improve overall business operations and efficiencies - beyond IR.
Orient: Evaluate what’s going on in the cyber threat landscape & inside your company. Make logical connections & real-time context to focus on priority events.
Incident Triage; Situational Awareness; Threat Intelligence; Security Research
- Is our company rolling out a new software package or planning layoffs?
- Have we (or others in our industry) seen attacks from this particular IP address before?
- What’s the root cause?
- What’s the scope and impact?
Get inside the mind of the attacker so that you can orient your defense strategies against the latest attack tools and tactics. These are constantly changing so make sure you have the latest threat intelligence feeding your security monitoring tools to ensure that they are capturing the right information and providing the necessary context.
Bonus tip: Avoid the distraction (and lunacy) of “attack back” strategies… you have enough work to do.
Decide: Based on observations & context, choose the best tactic for minimal damage & fastest recovery.
Your Company’s Corporate Security Policy ; Hard copy documentation (notebook, pen, and clock)
- What do we recommend doing based on the facts available to us?
Document all aspects of the incident response process, especially communications regarding data collection and the decision-making processes.
Bonus tip: Use incident response checklists for multiple response and recovery procedures, the more detailed, the better. We cover the essential ones in chapter three.
Act: Remediate & recover. Improve incident response procedures based on lessons learned.
Data capture and forensics analysis tools; System backup & recovery tools; Patch mgmt. and other systems mgmt; Security Awareness Training tools and programs
- What’s the quickest way to remedy affected systems and bring them back online?
- How can we prevent this in the future?
- How can we train users better so that these things don’t happen again?
- Does our business process get adjusted based on these lessons?
Training, communication, and continual improvement are the keys to success in acting effectively during an incident. Team members should know what is expected of them and that means in-depth training, detailed run-throughs, and keen attention on how to continually improve teamwork and the overall process.
Bonus tip: Use incident response checklists for multiple response and recovery procedures. The more detailed, the better.
Incident Response Procedures: The Need for Checklists
One of my former bosses was also a former pilot, and so of course, we had a checklist for everything. And after going through one too many real fires (not to mention fire drills), I can safely say I’m really glad we had them. And I can also safely say that they were constantly being edited for clarity and efficiency – after training exercises, and after real incidents. There was always a better way to do something, and certainly a better way of explaining how to do it.
So… what kind of incident response checklists will I need?
Yes, that’s the right question. Because there will definitely be more than one single incident response checklist. The best checklists are those that apply to specific scenarios and break down a specific
task or activity into bite-site chunks. They may also involve a few meandering offshoots – or “if then” – branches off your main checklist, and that’s likely where the richest detail will be necessary. Keep in mind though that you may not be able to predict all incident scenarios, and these checklists won’t necessarily capture everything that could happen.
Every business operation will dictate what’s considered essential for that specific business, because the critical business systems and operations to recover first will be different. That said, there are a few general types of checklists that can be considered essential for any business. Here are a few examples, along with a few references for additional information.

Forensic analysis checklists (customized for all critical systems)
During the process of investigating an incident you’ll likely need to look deeper at individual systems. A checklist that provides useful commands and areas to look for strange behavior will be invaluable. And if your company is like most, you’ll have a mix of Windows and Unix flavors. Customize each checklist on an OS basis, as well as on a functional basis (file server vs. database vs. webserver vs. domain controller vs. DNS).
Some useful references: SANS Incident Handling Handbook and Lenny Zeltser's Security Checklists
Emergency contact communications checklist
Don’t wait until an incident to try and figure out who you need to call, when it’s appropriate to do so, how you reach them, why you need to reach them, and what to say once you do. Instead, develop a detailed communication plan with the specifics of when to put it into place and don’t forget to get overall consensus on your approach. The entire incident response team should know whom to contact, when it is appropriate to contact them, and why. In particular, review the potential worst case scenarios (e.g. an online ordering system going down right in the middle of Cyber Monday) and identify the essential staff who can get these critical systems back online, as well as the management team who will need to remain updated throughout the crisis.
Bonus tip: You’ll also need to document when it is or is not appropriate to include law enforcement during an incident, so make sure you get the necessary input and expertise on these key questions.


System backup and recovery checklists (for all OSes in use, including databases)
Each system will have a different set of checklist tasks based on its distinct operating system and configurations. It’s also important to note the time it takes for each step required to restore operations, and also test full system backup and full system recovery while you’re documenting each checklist. There should also be specific steps listed for testing and verifying that any compromised systems are completely clean and fully functional.
“Jumpbag” checklists
SANS, one of the premier sources of information for the incident responder, recommends that each incident response team member have an organized and protected “jump bag” all ready to go that contains the important tools needed for a quick “grab-and-go” type of response. Their recommended items include:
- An Incident Handlers Journal to be used for documenting the who, what, where, why, and how during an incident
- Your incident response team contact list
- USB drives
- A bootable USB drive or Live CD with up-to-date anti-malware and other software that can read and/or write to file systems of your computing environment (and test this, please)
- A laptop with forensic software (e.g. FTK or EnCase)
- Anti-malware utilities
- Computer and network tool kits to add/remove components, wire network cables, etc. and hard duplicators with write-block capabilities to create forensically sound copies of hard drive images.


Security policy review checklist (post-incident)
The most important lessons to learn after an incident are how to prevent a similar incident from happening in the future. In addition to potential updates to your security policy, expect incidents to result in updates to your security awareness program because invariably, most incidents result from a lack of user education around basic security best practices. At the very least, this checklist should capture:
- When the problem was first detected, by whom, and by which method
- The scope of the incident
- How it was contained and eradicated
- The work performed during recovery
- Areas where the incident response teams were effective
- Areas that need improvement:
- Which security controls failed (including our monitoring tools)?
- How can we improve those controls?
- How can we improve our security awareness programs?
The Need for Incident Response Forms & Surveys
As we’ve mentioned several times already, you’ll need to document many things during your job as an incident responder. The best way we’ve seen to capture an accurate, standard, and repeatable set of information is to do it with a form. And, thankfully, SANS has provided a form for every type of security incident tidbit you’ll need from contacts to activity logs with specific forms for handling intellectual property incidents.

Navigate Your Journey:

Incident Response Myth Busting for Executives
Myth #1: An incident response process begins at the time of an incident
Truth: Actually, an incident response process never ends. It’s a continual process, like other business processes that never end.
Advice: Give your executives some analogies that they’ll understand. For example, an incident response process is like a subscription-based business model, e.g. software-as-a-service. It’s always on. It’s important to point out that there will be stages of criticality for incidents, some that will require more serious reporting and external involvement, and some that won’t. See Chapter 3 for more details on this.
Myth #2: Each “incident” is a discrete, monolithic event, which may occur 1-2 times a year
Truth: As many of us know, we’re constantly working on incidents. Evaluating log files, investigating outages, and tweaking our monitoring tools at the same time. Some of these are related to each other, and some aren’t. And again, it’s constant, daily work.
Advice: Explain - at a high level - how incident response works. As a continual process, it’s a daily activity, that moves from high level investigations and pivots to specific abnormalities or outages, sometimes developing into something more significant, and sometimes not. Share an example of a specific investigation and offer to provide weekly updates on incident response process metrics, cyber security threat trends, system performance data, user activity reporting, or any other information that would be relevant for the executive team.
Myth #3: We haven’t had any incidents yet, so why do we even need this tool or that resource?
Truth: It’s hard to believe, but there are still skeptics about the very real cyber security risks facing us, and the even more real possibility of becoming the next victim. When it comes to cyber security, looking at past experience reveals nothing about what could happen in the future, particularly considering the pace of innovation happening in cyber crime.
Advice: Time for more executive education. Point out that you’ve done your best to mitigate major risks up until this point, but the adversary continues to up their game. It’s sort of like that moment in Jaws, “you’re going to need a bigger boat!”