Alert fatigue is a real problem in IT Security. This can set in at the worst time, when an analyst checks their tools and sees yet another event, or even another 50-100 events, after they just checked. They click through events looking for the smallest reason they can find to dismiss the event so they won’t need to escalate, or further investigate, the issue.
They’ve been through this before, they can see where the real problems are, and they just want to get rid of these events and continue getting other work done. Unfortunately, as many know, one innocent looking event could put you on the trail of a bad actor in the environment. Each event must be investigated thoroughly to make sure that there is no evidence of an incident.
Going through alerts multiple times, the fact that they can be very similar is a large part alert fatigue. Another part of the cause is false positives. Analysts may find it difficult to maintain vigilance when the majority of events that they go through are false positives. There are new technologies that have come out that claim they are able to reduce the number of false positives. While they may, or may not, be effective in ingesting alerts and identifying true positives, this only adds on to the workload of analysts, creating yet another tool to log into and get alerts from.
There are also many articles currently about alert fatigue within cybersecurity. An article from Tripwire describes alert fatigue as a combination of too many false positives as well as a reason to raise the security awareness of your organization. Another article from CSO notes that a large number of organizations deal with too many false positives that overload their analysts. This article goes a step further and advises on several steps that can be taken to help reduce the risk of alert fatigue. These are definitely good steps to help your organization improve its ability to respond to alerts and reduce analyst workload. I recommend reading through and seeing what can be done.
Tuning
I would also add one more step: tuning. This seems obvious, but it is often overlooked. Let me first tell you what I mean by tuning. Tuning is a combination of reducing false positives, working with alerts, and correlating events and trends to ensure greater accuracy. Each of these helps the analyst by refining alerts being looked into. Tuning needs to be a balanced approach that will reduce the number of unnecessary events received and ensure that there are no blind spots an attacker can take advantage of to slip by unnoticed.
The first step of tuning is to figure out what is important to alert on and what is not. In my opinion there is a big section of alerts that can be immediately kicked out of the analyst’s queue. That would be any blocked attacks. Attacks that are blocked by the technology guarding the perimeter and internals of the network and endpoints can be a great story to executives and can even give you trends and areas to look at to make sure that nothing else is needed for protection. However, the alerts that are generated that say something was blocked just add to the data that has to be looked into if sent to the analyst.
What Alerts Do You Care About?
Removing blocked attacks helps the analyst pay more attention to potential incidents that were not stopped. After you’ve done that, the next matter of importance is: what alerts do you care about? To determine that takes a bit of research. You need to determine what impacts you the most, down to what could be a threat but may, or may not, be worth investigating. That involves knowing:
- where sensitive information is located
- how it can be accessed, how it should be accessed (two very different things)
- who has access
- what traffic is normal on the network
- what should be on the endpoints, (the security baseline for endpoints)
- and many other variables
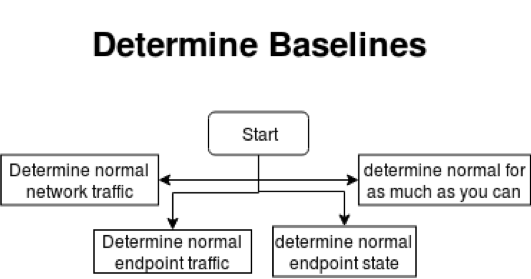
This part is by far the longest part of the tuning process, and don’t think that the information is static. Once you have gathered this information you will need to lay down policies, standards and procedures for when a department or vendor changes how they interact with the network and endpoints. Be aware though, even if you manage to get those standards out, you will most likely be the last one to know what changes were made and why. Being adaptable to change is key. This is the baseline for your network.
Baseline Defines “Normal”
Our baseline gives us what is normal. However, we do not want to alert on something just because it deviates from the baseline. There are many events that will create a deviation that are not malicious in nature. We want alerts that are malicious and are causing a deviation. A dropper was successful, a computer seems to be sending encrypted data through an unapproved channel, etc.
You may also want to narrow focus down to targeted attacks. An example of this could be scanning activity. If you are scanning your endpoints with a vulnerability scanner, exclude it from alerting.
Threat Landscape
A more difficult challenge is determining what outside attacks are targeted on your industry, or even your organization. This is where threat intelligence (threat feeds) can assist. It can help narrow your focus. A more recent item that may help with your focus is GreyNoise.io. This feed asserts itself as “anti-threat intelligence” and can help you on your alerting by reporting on widespread and non-targeted events. Essentially use them to help you exclude what is not targeted at you directly.
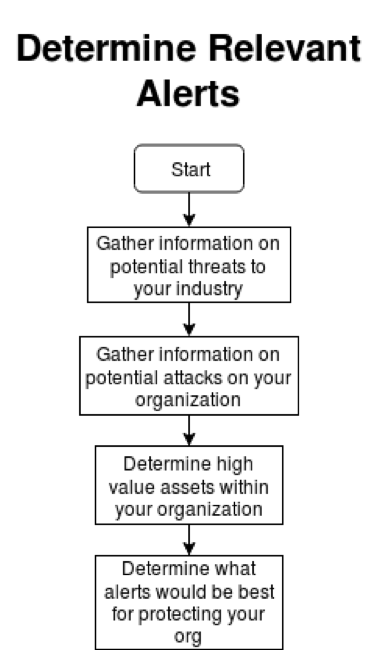
In order to determine what alerts are valuable you need to know what is worth investigating. You need to know what the threat landscape is for your industry and your organization specifically. Once you have that information you will have a good idea what you should be on the lookout for. This is your threat landscape. If you take your threat landscape and apply that to the baseline of “known good” you will have a good idea of what alerts you need, what alerts would be useful, and how to configure those alerts to your organization. This, just like your baseline, is not a static target, and you must stay up to date on new threats and information. Once again, adaptability is key for success.
Tune for False Positives
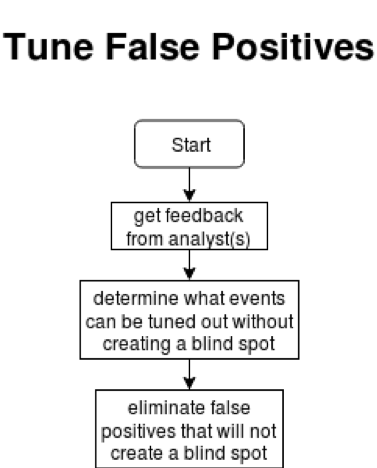
Congratulations, you now have a list of alerts that your analyst will be checking and watching for what matters to your organization. You aren’t through yet though. You will need to tune the technology for false positives, adapt to changes in the network, and keep on top of the ever changing threat landscape. Analysts are great sources of information in this. They can tell you what triggered that new false positive what might be new trend they are seeing, etc. Just remember, when tuning for a false positive you need to ensure that only the false positives are removed. If you tune too much one way you may be creating a blind spot.
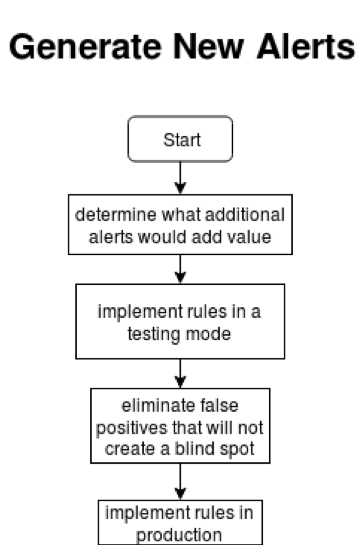
Once you have the alerts where you want them, and analysts have a stable (but not overwhelming) number of alerts you may want to start looking for opportunities to look at widening the net, taking a look at what else could be helpful to look at. Just make sure that you are not overly burdening your analysts.
I recommend implementing new alerts in a testing environment while making sure that you are the only one monitoring the new alert. That way you can tune your rule before you start acting on it. Doing it this way can help ensue you will deliver a rule that can be trusted immediately. Always keep in mind the goal of tuning is to protect your organization. This is only achievable when alerts are able to be investigated in a timely manner and analysts are able to look through events without doubting the validity of the alerts or becoming overwhelmed by the volume of alerts.
Management Support for Security Analysts
This is a completely tool/technology agnostic approach to tuning that is applicable and viable in any organization. But what if you already have a list of alerts that your analysts are looking at? Well the best approach is to ensure that you have management approval to implement a plan of action to review and replace your existing alerts using the process above.
That will help out in the long run, but there may be issues with this. Management may require that certain things are looked at due to historical issues. They may want alerts set up for specific circumstances. As most are aware, nothing can happen the ideal way. However, if you work together with your management you will be able to come up with a list of alerts and criteria that will work in everyone’s favor.
The support of your management team is important. Just like you, they weigh requirements they have been given with the associated risk to determine best practices. Improving visibility while reducing the risk of alert fatigue is good for the organization and management. As such, common ground is not hard to find, and will ensure that no goals are missed through the tuning process.
Conclusion
Alert fatigue is something that is well documented and has several causes. Tuning can help with alert fatigue.
It takes effort, and like monitoring events, never really ends. However, it will make a huge difference in both the number and quality of the alerts. Before turning to other solutions, make sure that you are tuning the technologies that are already protecting your organization. You will notice a substantial difference by doing so, and you might find that you do not need the extra solutions.
With the goal of protecting your organization, you must take an active role in your technology. You need to enable your analysts by providing them well defined tuned alerts. This will both increase your security capabilities and help prevent alert fatigue.
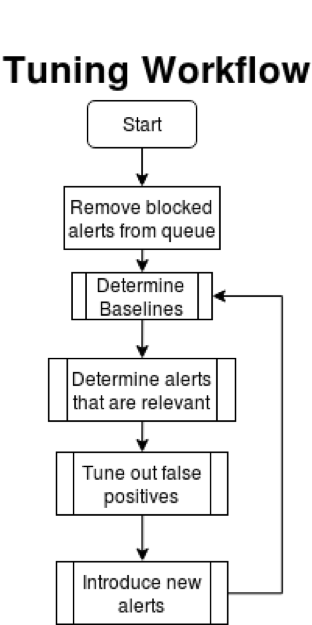
For easy reference I have an easy checklist to go through that will help you in the tuning process:
- Check the event queue that your analysts are going through each day.
- Remove the events that are blocked from the queue but analyze them for trends and potential targets and weaknesses within your organization.
- Determine the baselines on your network and endpoints.
- Determine your threat landscape and relevant alerts.
- Work with your analysts to tune out false positives.
- Determine what new alerts would be able to provide additional value to your organization and implement them only once they are tuned to an appropriate level.
- Stay vigilant and repeat steps 3 through 7.