 Role Availability Role Availability
|
 Read-Only Read-Only
|
Investigator |
 Analyst Analyst
|
Manager
|
In addition to the native service-specific logging that Amazon Web Services (AWS) provides, individual applications you run in the AWS environment often generate their own log files. You can forward these logs to an Amazon Simple Storage Service (S3) bucket and configure USM Anywhere to collect logs from that Amazon S3 bucket. USM Anywhere does not restrict the number of logs you can collect, but AWS does set limits on the number of logs it can return in each operation.
For example, to collect logs from AWS Web Application Firewall (WAF), you first need to follow AWS documentation to configure AWS WAF logging to store logs in an Amazon S3 bucket. Then configure a scheduler job in USM Anywhere to collect logs from the bucket.
Note: USM Anywhere accepts any file type when collecting log files. For compressed files, it looks for the file extension .gz, .zip, or .bz2 and uses the standard java.util or Apache Commons library to read the files. All other files are read as plain text.
To collect logs from an Amazon S3 bucket
- Go to Settings > Scheduler.
-
In the left navigation menu, click Log Collection.
Note: You can use the Sensor filter at the top of the list to review the available log collection jobs on your
-
Click Create Log Collection Job.

Note: If you have recently deployed a new USM Anywhere Sensor, it can take up to 20 minutes for USM Anywhere to discover the various log sources. After it discovers the logs, you must manually enable the
The Schedule New Job dialog box opens.

-
Enter the name and description for the job.
The description is optional, but it is a best practice to provide this information so that others can easily understand what it does.
- Select Sensor as the source for your new job.
- In the Action Type option, select Amazon Web Services.
- Select a sensor if you have more than one installed in your environment.
-
In the App Action option, select Monitor S3 Bucket.

-
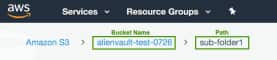
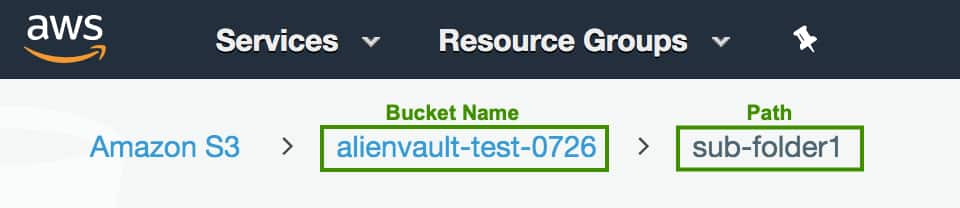
Enter the Bucket Name and Path.

The bucket name is the name of the Amazon S3 bucket as configured in your AWS account, such as alienvault-test-0726 in the screenshot below.
The path is the path prefix within the Amazon S3 bucket, such as sub-folder1 in the screenshot below. This does not include the bucket name.
Note: Logs from the directory and its subdirectories are collected.
Important: If you have selected Elastic Load Balancer (ELB), Application Load Balancer (ALB), or Cloud Trail sources, then you need to use, inside the path field, the same prefix you have introduced in your AWS configuration. If the prefix field is empty in your AWS configuration, then you must leave the path field inside USM Anywhere empty.
-
In Source Format, select either of the following log formats:
- syslog: Standard format for transmitting log data to USM Anywhere.
-
raw: Use for non-syslog formatted data.

-
In the Schedule section, specify when USM Anywhere runs the job:
-
Select the increment as Minute, Hour, Day, Week, Month, or Year.
Warning: After a frequency change, monitor the system to check its performance. For example, you can check the system load and CPU. See USM Anywhere System Monitor for more information.
-
Set the interval options for the increment.
The selected increment determines the available options. For example, on a weekly increment, you can select the days of the week to run the job.

Or on a monthly increment, you can specify a date or a day of the week that occurs within the month.

-
Set the start time.
This is the time that the job starts at the specified interval. It uses the time zone configured for your USM Anywhere instance (the default is Coordinated Universal Time [UTC]).
Important: USM Anywhere restarts the schedule on the first day of the month if the option "Every x days" is selected.
-
-
Click Save.
USM Anywhere detects any enabled jobs with the same configuration and asks you to confirm before continuing. This is because having two jobs with the same configuration generates duplicate events and alarms.
- In the AWS console, restart the AWS Sensor instance so that it detects the new configuration.
You can confirm that the scheduled job is collecting logs by going back to Settings > Scheduler > Log Collection and expanding the job you've created. Each log collection event will be listed under Schedule History.







Moving Logs from an Amazon EC2 Instance to an Amazon S3 Bucket
In Amazon Elastic Compute Cloud (EC2), it can be difficult to create direct network connections between isolated parts of your environment. Amazon S3 provides a convenient way to move application logs from an Amazon EC2 instance to an Amazon S3 bucket. Amazon S3 buckets are used to store objects that consist of data and metadata that describes the data. You then configure the AWS Sensor to retrieve and process the log files.
You'll want to synchronize logs from your instance with an Amazon S3 bucket. There are multiple ways to do this. The easiest method is to use the AWS Command Line Interface (CLI) as documented by Amazon. You then create a script similar to the following example and configure it to run periodically as a cron job.
aws s3 sync "<path_to_log>" "S3://<bucket_name>/<storage_path>/"
 Feedback
Feedback